
base64隐写
base64编码
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。
规则
关于这个编码的规则:
①把3个字节变成4个字节。
②每76个字符加一个换行符。
③最后的结束符也要处理。
eq
转换前 11111111, 11111111, 11111111 (二进制)
转换后 00111111, 00111111, 00111111, 00111111 (二进制)
上面的三个字节是原文,下面的四个字节是转换后的Base64编码,其前两位均为0。
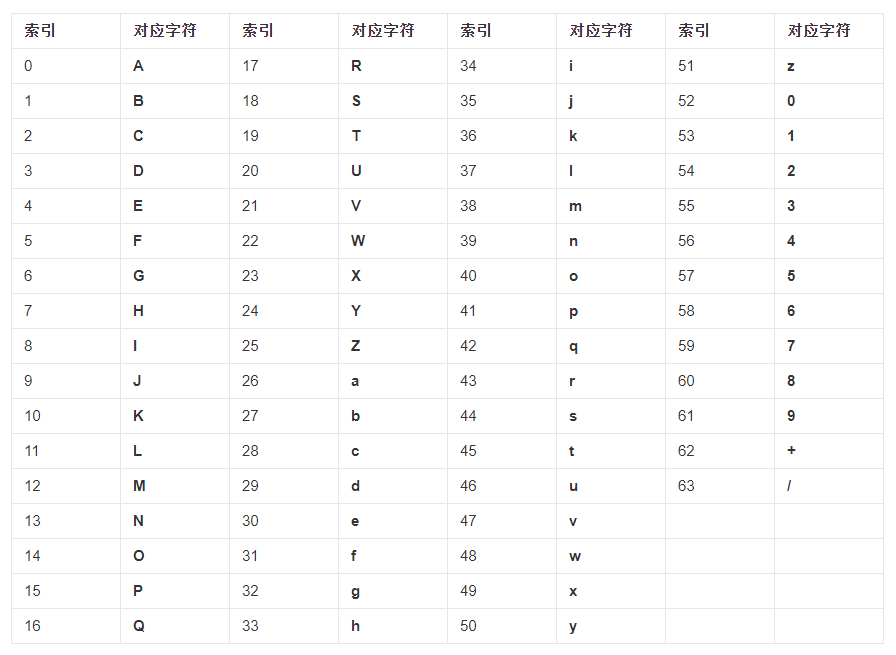
转换后,查表获得密文
base64隐写
Base64解码的过程:
①丢掉末尾的所有‘=’;
②每个字符查表转换为对应的6位索引,得到一串二进制字符串;
③从头开始,每次取8位转换为对应的ASCII字符,不足8位则丢弃。
在③中,会有部分数据被丢弃(即不会影响解码结果),这些数据正是我们在编码过程中补的0(本文第三第四张图中加粗的部分)。也就是说,如果我们在编码过程中不全用0填充,而是用其他的数据填充,仍然可以正常编码解码,因此这些位置可以用于隐写。
解密脚本:
#coding:utf-8
def get_base64_diff_value(s1, s2):
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
res = 0
for i in xrange(len(s2)):
if s1[i] != s2[i]:
return abs(base64chars.index(s1[i]) - base64chars.index(s2[i]))
return res
def solve_stego():
with open('base64隐写文件', 'rb') as f:
file_lines = f.readlines()
bin_str = ''
for line in file_lines:
steg_line = line.replace('\n', '')
norm_line = line.replace('\n', '').decode('base64').encode('base64').replace('\n', '')
diff = get_base64_diff_value(steg_line, norm_line)
print(diff)
pads_num = steg_line.count('=')
if diff:
bin_str += bin(diff)[2:].zfill(pads_num * 2)
else:
bin_str += '0' * pads_num * 2
print(goflag(bin_str))
def goflag(bin_str):
res_str = ''
for i in xrange(0, len(bin_str), 8):
res_str += chr(int(bin_str[i:i + 8], 2))
return res_str
if __name__ == '__main__':
solve_stego()